Less Free Parameters = Better Science
Unzicker says "Cosmology’s 'concordance model' uses six numbers, which are called 'free parameters' because they cannot be explained within the model but rather are fitted to the measurements. The standard model of particle physics needs not only six of them, but an impressive 17. Why 17?.. In the 1950s, a boom of particle accelerators started producing hundreds of elementary particles with spectacular collisions. In the following decades, particle physics has been busy classifying this zoo and reducing its mathematical description to 'only' 17 parameters. A few Nobel prizes have even been handed out because of this work. But should we be convinced that we have come to understand the ultimate structure of matter? In his book The Trouble with Physics, Lee Smolin comments on the 17 free parameters. 'The fact that there are that many freely specifiable constants in what is supposed to be a fundamental theory is a tremendous embarrassment.'"
Smolin and Unzicker are right.. the "constants" or "free parameters" represent our ultimate ignorance about the world. Those parameters are basically knobs you can turn to make our formulas "fit" the experimental data. They are reverse engineered from data, they do not arise from fundamental mathematical deduction.
I'll give an example. Let's say a scientist is looking at some data collected from nature,
df = u.data_synth_1()
df.plot(grid=True)
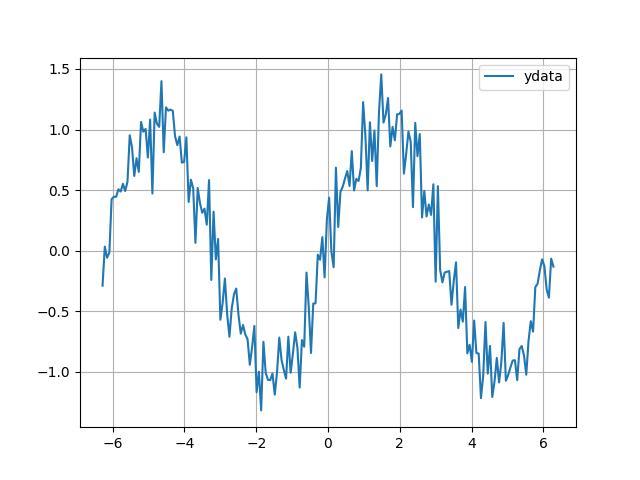{kind=link}
And he is asked to find the formulation for this. He looks at the data and says, "well I can represent this by simply multiplying powers of $x$ with some coefficients", eg $c_0 x + c_1 x^2 + ... + c_n x^n$. He thinks he is smart because you can represent any curve with such a function.
He pulls some numbers out of his ass,
$c_0 = -0.00003$,$c_1=-0.00001$,$c_2=0.004$,$c_3=0.0003$,$c_4=-0.12$, $c_5=-0.005$,$c_6=0.4$,$c_7=0.04$
.. and uses them,
degree = 7
coef = [-0.00003,-0.00001,0.004,0.0003,-0.12,-0.005,0.4,0.04]
df['ypred'] = np.polyval(coef,df.index)
df.plot(grid=True)
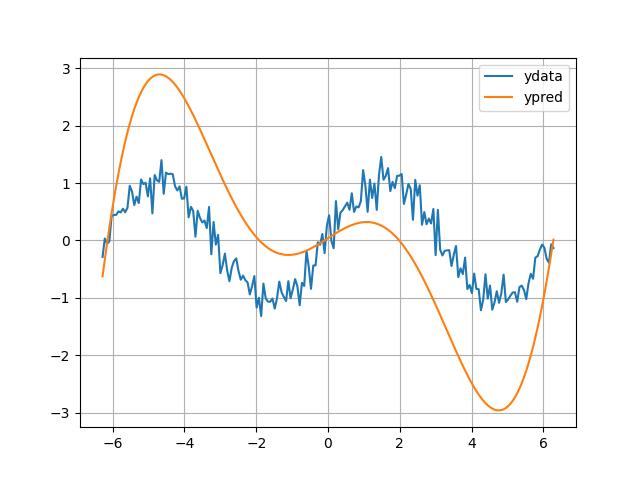{kind=link}
He obtains the graph above. His "prediction" came close in some places, though overall not great.
Then the genius says "I can reverse engineer those adjustable knobs
from data!". He uses polyfit, and voila
coef = np.polyfit(df.index, df.ydata, degree)
df['ypred'] = np.polyval(coef,df.index)
df.plot(grid=True)
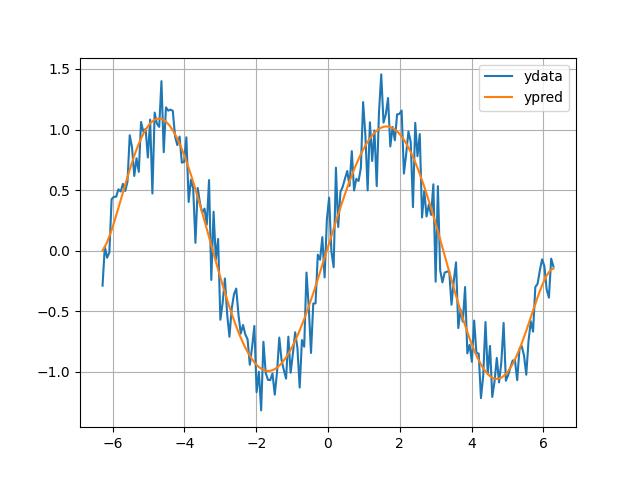{kind=link}
That is a good fit
But the 7 coefficients tell us nothing in scientific terms because using the same coefficients / free parameters / "constants" approach I could turn the curve into a line, I could make it go up, or down. The structure of my "flexible (too flexible)" formulation doesn't tell me anything about the phenomena. Those free parameters represent our ignorance, not knowledge.
Now we reveal where the data comes from: it is the SINE FUNCTION (with some added noise to make it look like experimental data).
df['ypred'] = np.sin(df.index)
df.plot(grid=True)
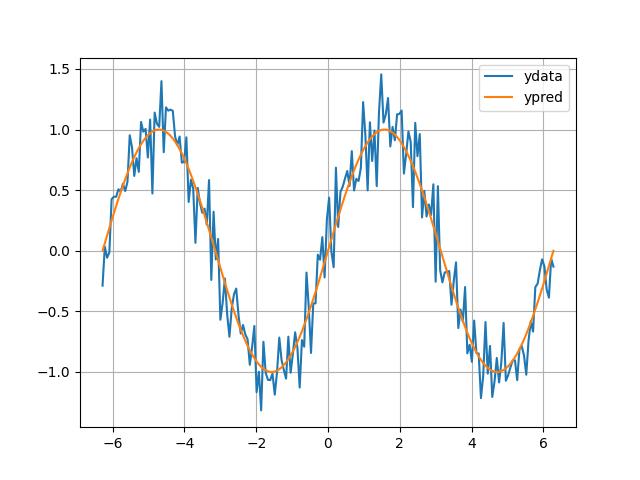{kind=link}
The sine function, $y = sin(x)$, has no free parameters. It is simpler, even faster to compute. However it requires the knowledge of trigonometry. Because the foolish scientist did not know this, his formulation became parameter heavy. The model with a lot of adjustable knobs represented his ignorance.
Don't get me started on LLM tech, they are all about adjustable parameters, a modern LLM has over 1.5 trillion of them. Imagine the level of ignorance captured in that design decision. We basically know next to nothing about intelligence, we just reverse engineered some parameters from data via a black box, and called it AI.